

Major Announcements From Splunk Bring Observability and Security to the Forefront
Observability and security have come to the forefront of IT service delivery, a convergence that was long overdue. This was the urgent theme of the 2022 Splunk conference in Las Vegas.

Atlassian Outage – Thoughts on What to Do When Your Provider Goes Down
The latest Atlassian outage goes to show that every cloud provider is prone to unplanned downtime sooner or later. While every company strives to achieve that unicorn status of zero downtime, it is almost impossible to achieve that in the face of “Unknown Unknowns.” I analyze it and offer some solutions on how to mitigate that if disaster strikes you.

Crisis/Incident Management in the Digital Era
When it comes to crisis and incident management in the cloud/digital era, HOPE IS NOT A STRATEGY! A properly setup Incident Management process should identify the incidents, provide you with Root Cause Analysis (RCA), propose possible fixes, and escalate the issue to the right SRE, DevOps, SME in a matter of minutes.

In Digital Economy, You Should Fail Fast, But Must Also Recover Fast
In digital economy, you must move fast to survive. Not in six-month release cycles. But moving with fast release cycles, continuous releases, a mature CI/CD pipeline is only a portion of the solution. If you continue to break your systems at a faster rate but are unable to fix them faster as well, you are setting up for unplanned disasters that will hurt your business sooner than later. I discuss some of the fixes in this blog.

Report: Data Done Right for AIOps with RDA
Most of the AIOps companies are doing the process right, some use AI and ML properly, but most fail on how to automate data processing, or DataOps, on how to get the right data to AIOps tools at the right time. In this eBook "Data Done Right for AIOps," I discuss this in detail and offer some possible solutions including Robotic Data Automation (RDA).

Report: Observability deep dive report for Zebrium
Summary I did a deep dive vendor research report on Zebrium which specializes in automatic root cause analysis using machine leaning. Quick summary from the report: Zebrium is an Observability/AIOps platform that uses unsupervised machine learning to auto-detect software problems and automatically find root causes, reducing manual labor and speeding […]

Achieving Reliable Observability Part 1 – Making Cloud-Native Observability More Robust
I was having a conversation with a CxO level customer as part of an AIOps/Observability workshop, and from what I could tell, most are confused about how to properly operationalize cloud-native production environments – especially the monitoring/observability portion. Here is how the conversation went.
Comprehensive observability is core to future-proofing your IT infrastructure
Observability is an emerging set of practices, platforms, and tools that goes beyond monitoring to provide insight into the internal state of systems by analyzing external outputs. Monitoring has been a core function of IT for decades, but old approaches have become inadequate for a variety of reasons—cloud deployments, agile development methodology, continuous deployments, and new DevOps practices among them.
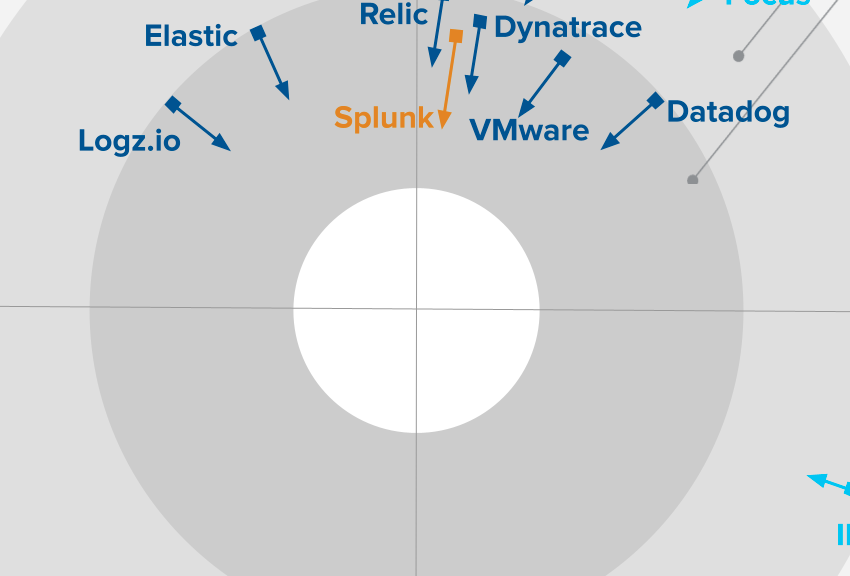
Report: GigaOm Radar for Cloud Observability
Summary Observability is an emerging set of practices, platforms, and tools that goes beyond monitoring to provide insight into the internal state of systems by analyzing external outputs. It’s a concept that has its roots in 19th century control theory concepts and is rapidly gaining traction today. Of course, monitoring has been […]
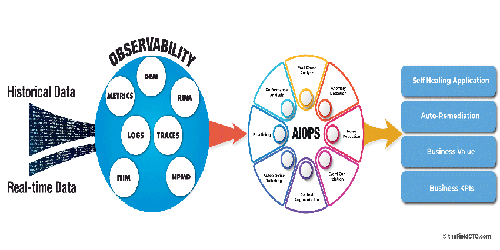
AIOps vs Observability vs Monitoring – What Is The Difference? Are You Using The Right One For Your Enterprise?
This article was originally published in Forbes on Feb 2, 2021 In the last few months, I have been analyzing and writing a research report for GigaOm in this space, which is due to be released soon. I looked at about 30+ vendors in this space as part of that […]