
Report: Key Criteria for Evaluating Cloud Observability






An Evaluation Guide for Technology Decision Makers by Andy Thurai and David Linthicum
Summary

The concept of observability has evolved over the years, referring to the ability to monitor the internal states of systems using the externally exhibited characteristics of those systems. It provides the ability to predict the future behavior of those systems using data analysis and other technologies.
By monitoring what has already happened, enterprises can reactively fix the issues. Observability, in contrast, helps predict issues before they surface, thus helping to build a proactive enterprise. Ultimately, by automating observability, it’s possible to build hyper-automated, self-healing enterprises that fully understand what’s happening within the systems under management, and to predict and respond to likely outcomes.
Observability is important in the management and monitoring of modern systems, especially because modern applications are built to be quick and agile. The widespread practice of bolting on monitoring and management after applications are deployed is no longer sufficient. Thus, the notion of observability includes the implementation of modern instrumentation designed to help users better understand the properties and behaviors of an application.
It should be noted that monitoring and observability are not the same thing. Monitoring involves the passive consumption of information from systems under management. It uses dashboards to display the state of systems, and is generally purpose-built for static systems or platforms that don’t change much over time.
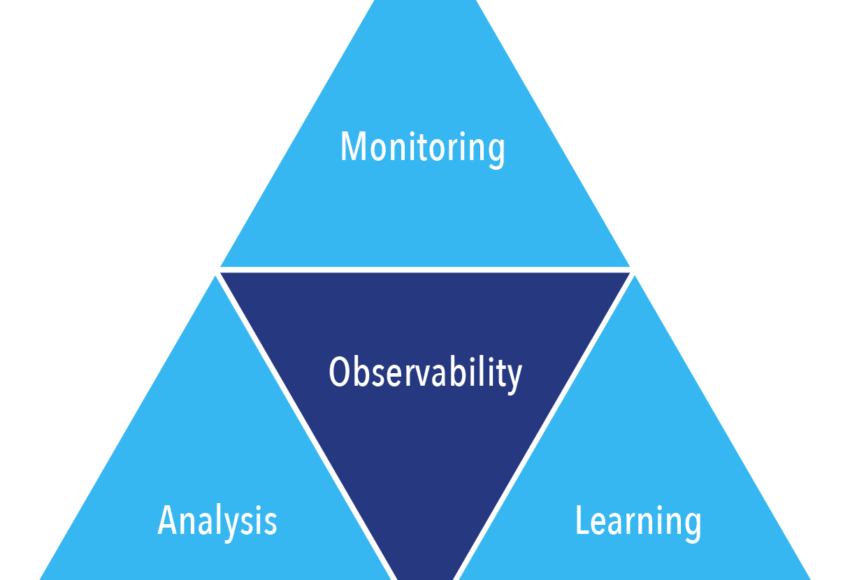
In contrast, observability takes a proactive approach to revealing system attributes and behavior, asking questions based on a system’s internal data. The technology is purpose-built for dynamic systems and platforms with widely changing complexity. An important feature of observability is the ability to analyze “what if” scenarios and trending applications to predict a possible future failure (See Figure 1).

Figure 1: Observability Is Built on Monitoring, Analysis, and AI-Enabled Learning Systems
Why is Cloud Observability So Important Now?
The insight that observability grants is particularly important because the way new applications are built and architected has changed over the years:
- Cloud-based applications depend on multiple services, often via RESTful APIs and microservices.
- Serverless and service-based applications have little visibility into underlying infrastructure.
- Applications are highly distributed, typically based on containers and microservices, with the ability to scale up and down in seconds.
- Hybrid and multi-cloud architectures that depend on multiple providers, in-house and external, are exceedingly complex and difficult to track.
Most monitoring and operations tools, including AIOps tools, claim some role in observability, but in some respects it’s like slapping a new label on an old nostrum. However, if you consider observability as a concept, not as a set of tools and technologies, you get a better idea of the value. For instance, observability means using analytical views that take raw data, provide a holistic view, find patterns in the data, make calculated predictions, and react to those predictions using automated and non-automated responses.
Observability should provide a full view of the enterprise, including on-premises, multi-cloud and hybrid cloud environments. The successful use of appropriate tools can help eliminate the cloud complexity issues that hinder some cloud migrations and new development.
The Emerging Observability Sector
One of the more important topics covered in this Key Criteria report and in the GigaOm Radar for Cloud Observability report is how to sift through the technologies that claim to have observability nailed. At present, the providers generally take different approaches, and while you can indeed find common patterns, it’s still difficult to compare apples to apples.
More tools are purpose-built for observability today, including most of the emerging AIOps toolsets, as well as other monitoring technologies like application performance monitoring (APM), network performance monitoring and diagnostics (NPMD), digital experience monitoring (DEM), and infrastructure monitoring, which have the ability to deal with complex operational data.
However, while all of these technologies claim to be built for observability, most are repurposed monitoring and management tools, the original use of which involved anything to do with bringing operational data to a single view. Therefore, we have a few ways to consider the observability market, including:
Traditional Monitoring Tools: These have been upgraded to provide modern services, such as storage and analysis, plus machine learning to support the notion of observability. These tools may be decades old but, generally speaking, have the advantage of providing better legacy systems integration.
Purpose-Built Observability Tools: These are typically focused on the acquisition and analysis of system data to report and respond to observations. They are generally data-first tools that may or may not have automated responses to analytical findings. Those without automation may expose an API that can be leveraged programmatically to deal with automation needs.
Hybrid Observability Tools: These are a mix of traditional tooling and more modern purpose-built observability tools, typically a combination of two or more technologies, created either through an acquisition or a strategic partnership. The risk with these is that you’re dealing with two or more tools that have their own independent paths and business interests and you may not be able to count on their continued functionality.
The logical features and functions found in most observability tools are depicted in Figure 2. Such tools need a place to store logs and other data for trending, correlation, and analysis. They need an analytics engine to determine patterns and trends. They typically include machine learning and AI systems to provide deeper knowledge management, as well as the ability to get smarter as they find and solve problems. Finally, they typically perform automation through an event processing system, which could be as simple as an API or as complex as a full-blown development environment that supports event orchestration.

Figure 2: Elements of an Observability System
Cloud Observability Findings
This report covers various aspects of observability, including how to plan, how to pick the right technologies, how CloudOps works in multi-cloud and hybrid cloud environments, and what operations and tooling you will need to be successful. Among the conclusions reached in this report are:
Observability is an advanced concept, and cloud observability tools are often not deployed correctly. Moreover, the skills needed for planning, building of the models, gathering system data, and proper deployment are frequently unavailable, all but ensuring failure on the part of many organizations.
Those leveraging observability tools typically don’t employ them to their maximum potential, especially with regard to using machine learning subsystems effectively. This limits the potential benefits an organization can accrue in terms of staying ahead of systems issues.
When leveraged correctly, observability tools potentially can increase systems reliability 100-fold because issues are automatically discovered, analyzed, and corrected—without human intervention. Moreover, the system is able to learn from successes, so system reliability improves over time. Proper observability tools and optimized IT processes can reduce the mean time to resolution (MTTR) metric between 50% to 90%, an important KPI to measure with modern “always on” systems.
The cloud observability market includes dozens of tools that claim to support the concept, but often these tools have very different primary missions, such as network, application performance, logging, or general operational monitoring. The lack of any real feature/functionality standards is causing many enterprises to wait for the market to normalize. The Open Telemetry initiative by the Cloud Native Computing Foundation (CNCF) is one such effort that is gaining traction. Most vendors in our report seem to have adopted or in the process of adopting it.
The push to move systems quickly to the cloud increases both complexity and risk, making observability more critical. This will likely persist for the next several years.
Organizations change over time, and their systems need to be able to change as well. Thus, extendable and configurable tools are a huge advantage.
This report that is co-written by myself and David Linthicum can be accessed here if you are a GigaOm subscriber or client. Otherwise, reach out to me, I will see what I can do to get you a copy of the report.